...years later...
you should try a tally table for stuff like this - remember that SQL is built on set theory...it wants to play with sets...
You want to capitalize each character in a string when the character in question happens to be the first character in a word within a string. So first you need to break the string into a set. This is where the tally table becomes useful because you can instantiate a table via a cte. A few other considerations. SQL doesn't know what a word is unless you signify the word and this is where things get tricky. Should you assume that the preceding character is always a space? What about the first character? What about those instances where you have hyphens-between-the-words or those instances where you have under_scores?
You can create a function where you mark these explicitly in the text which is fine depending on your needs but doesn't scale in a lot of different scenarios.
Because everyone forgets the m-dash. anyway...
This was my approach:
step 1 - use a cte to instantiate a tally table so i can break the string up into a table with each character in the string getting its own record.
step 2 - put everything in lower case so i can easily tell the engine what to upsize using the unicode function
step 3 - check to see if the first character of the entire string is a letter
step 4 - contractions are like curve balls in the dirt let's not forget those
step 5 - set everything else to lower case before wrapping back up into a string
create function [dbo].[tvf_CapsizeEachWord] (
@OriginalString varchar(8000)
)
returns table with schemabinding
return
with tally (n)
as
(
-- create a 8000 record tally table so that each charcacter has is parsed to a row
-- concat a space onto the beggining of the string because we are going to use it as an indicator later
-- also limit the tally table based on the length of the incoming string
select top (len(@OriginalString)) -- incase you tried to trick me by adding a space at the beginning of the string
row_number() over(order by (select null)) -- use rownumber function to be used as the sequencer later
from (values (0), (0), (0), (0), (0), (0), (0), (0)) as a(n) --8
cross join (values(0), (0), (0),(0), (0), (0), (0), (0), (0), (0)) as b(n) --80
cross join (values(0), (0), (0),(0), (0), (0), (0), (0), (0), (0)) as c(n) --800
cross join (values(0), (0), (0),(0), (0), (0), (0), (0), (0), (0)) as d(n) --8000
)
select Capsized = (
select ''+capsize
from (
select n
, capsize = case
when n = 1 and unicode(lower(substring(@OriginalString, n, 1))) between 97 and 122 -- unicode mapping for a through z
then upper(substring(@OriginalString, n, 1))
when substring(@OriginalString, n-1, 1) = '''' -- Don'T cap the character after an apostrophe
then lower(substring(@OriginalString, n, 1))
when unicode(lower(substring(@OriginalString, n, 1))) between 97 and 122 -- check to see if the character is a trhough z
and unicode(lower(substring(@OriginalString, n-1, 1))) not between 97 and 122 -- and the preceding character is not a letter
then upper(substring(@OriginalString, n, 1)) -- upsize it
else lower(substring(@OriginalString, n , 1)) -- everything else lower case
end
from tally
) as caps
order by n -- make sure you put the string back together in the proper order
for xml path(''), type).value('.', 'VARCHAR(8000)');
go
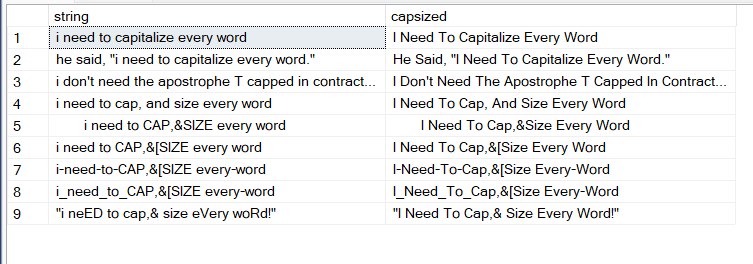
then to test the function we can decalre a table variable and insert some different strings so you can see how it functions.
declare @tsttbl table (
string varchar(8000)
);
insert into @tsttbl (string)
values ('i need to capitalize every word')
, ('he said, "i need to capitalize every word."')
, ('i don''t need the apostrophe T capped in contraction words i Don''t not want them lower cased')
, ('i need to cap, and size every word')
, (' i need to CAP,&SIZE every word')
, ('i need to CAP,&[SIZE every word')
, ('i-need-to-CAP,&[SIZE every-word')
, ('i_need_to_CAP,&[SIZE every-word')
, ('"i neED to cap,& size eVery woRd!"');
select string, caps.capsized
from @tsttbl as tst
cross apply dbo.tvf_CapsizeEachWord(tst.string) as caps

this will fail to have the desired effect on instances where your string is a structured like a quote within a quote block - where you would typically use singles quotes to wrap around a block of text when someone is quoting someone else. Anyway, play around with it.