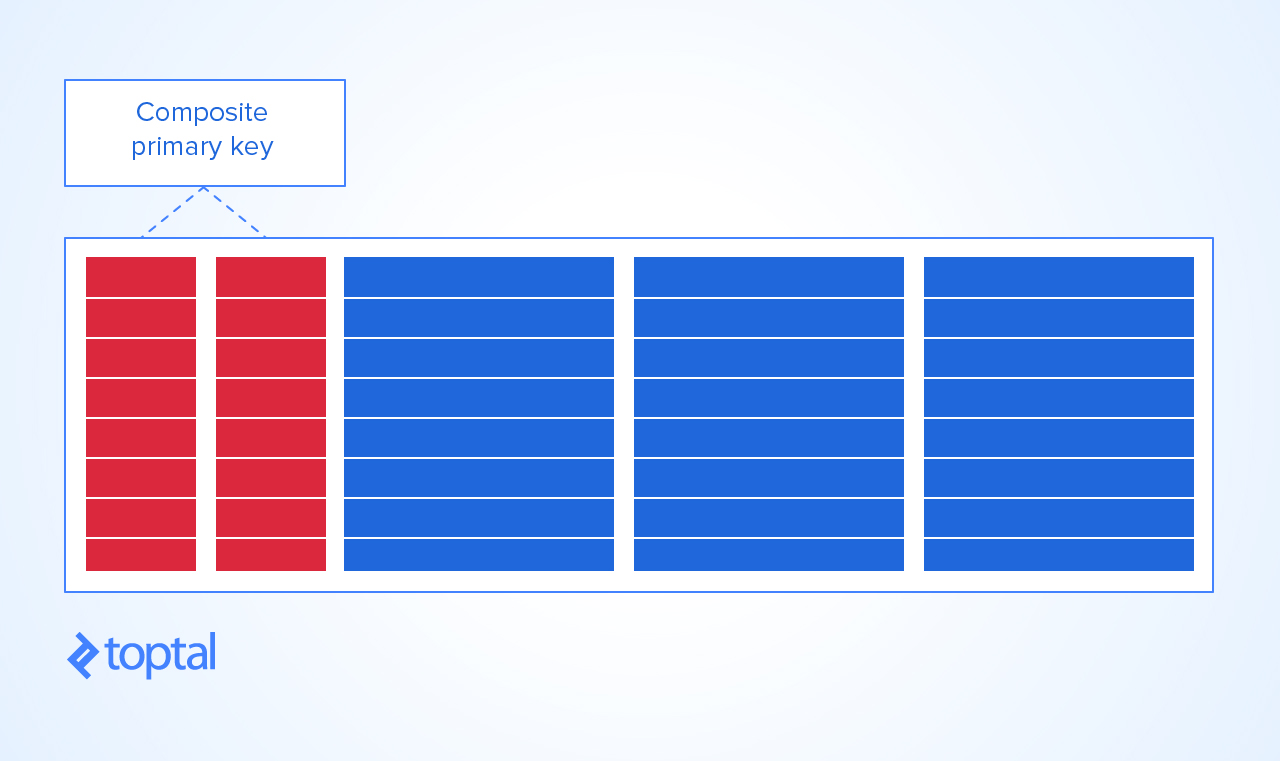
To say that "composite primary keys are bad practice" is utter nonsense!
Questions:
Composite primary keys are often a very "good thing" and the only way to model natural situations that occur in everyday life! Having said that, there would also be many situations where using a composite key would be cumbersome and unwieldy and therefore not an optimal choice.
Your questions are:
if composite primary keys are bad practice...?
Answered - they are definitely not bad practice!
and if not, in which scenarios is their use beneficial?
Benefits of a composite primary key
Here is an example of where composite keys represent a rational/beneficial choice as the primary key (PK) (indeed the only rational one as I see it).
Think of the classic Databases-101 teaching example of students and courses - the constraints are:
Create tables course and student:
CREATE TABLE course
(
course_id SERIAL,
course_year SMALLINT NOT NULL,
course_name TEXT NOT NULL,
CONSTRAINT course_pk PRIMARY KEY (course_id)
);
and:
CREATE TABLE student
(
student_id SERIAL,
student_name VARCHAR (50),
CONSTRAINT student_pk PRIMARY KEY (student_id)
);
I'll give you the example in the PostgreSQL dialect (and MySQL) - should work for any server with a bit of tweaking. You can find another more complex example here.
Now, you obviously want to keep track of which student is taking which course - so you have what's called a joining table (also called linking, bridging, many-to-many or m-to-n tables).
They are also known as associative entities in more technical jargon.
So, you create a joining table:
CREATE TABLE registration
(
cs_course_id INTEGER NOT NULL,
cs_student_id INTEGER NOT NULL,
-- now for FK constraints - have to ensure that the student
-- actually exists, ditto for the course.
CONSTRAINT cs_course_fk FOREIGN KEY (cs_course_id)
REFERENCES course (course_id),
CONSTRAINT cs_student_fk FOREIGN KEY (cs_student_id)
REFERENCES student (student_id)
);
Now, the only way to sensibly give the registration table a PK is to make that key a combination of course and student:
ALTER TABLE registration
ADD CONSTRAINT registration_pk
PRIMARY KEY (cs_course_id, cs_student_id);
Data integrity rules enforced by the compound PK
There is also:
a ready-made search key on course per student - AKA a covering index,
it is trivial to find courses without students and students who are taking no courses!
Now, you could, if you were finding that searches for student by course were slow, use a UNIQUE INDEX on (sc_student_id, sc_course_id).
ALTER TABLE registration
ADD CONSTRAINT course_student_sc_uq
UNIQUE (cs_student_id, cs_course_id);
There is no silver bullet for adding indexes
They:
will make inserts and updates slower, but at the great benefit of greatly improving select times.
will take up more space on disk.
Since a table containing registrations is likely only to be updated fairly infrequently relative to being searched, e.g. by lecturers grading assignments and students looking up their timetables, the performance hit on indexes will (probably) not be catastrophic.
Having two indexes may be overkill - that's up to the stakeholders to decide - as with many questions in IT, the answer to whether there should be two indexes is "It depends!". However, one thing is definitely an indisputable fact - there has to be a composite PK!
However, I would strongly suggest that not only is your database your data store, it is also the last bastion of your data integrity, so having the PK on the combination gives not only faster lookups but this automatically ensures the required constraints on enrolments/students outlined above.
It's up to the developer/DBA to decide which columns to index and when, given their knowledge, experience and analysis of the particular system, but to say that composite primary keys are always bad is just plain wrong and this is an example of where they are beneficial.
In the case of joining tables, composite primary keys are usually the only index that makes sense. Joining tables are also very frequently the only way of modelling what happens in business or nature or in virtually every sphere I can think of.
This is just a small example of where a composite PK can be a very good idea, and the only sane way to model reality. Off the top of my head, I can think of many many more.
An example from my own work
Consider a flight table containing a flight_id, a list of departure and arrival airports and the relevant times and then also a cabin_crew table with crew members.
The only sane way this can be modelled is to have a flight_crew table with the flight_id and the crew_id as attributes and the only sane PK is to use the composite key of the two fields.
That way you can't have the same person rostered to be on the same flight twice (receiving double flight-pay - I have seen this!)
See here for yet another example of how composite PKs can be useful - it involves people with different medical conditions:
- one patient can have 1-many conditions and
- one condition can affect 1-many patients (or even zero - there might be no cases of Ebola at a given moment?)
- a patient can only have a given medical condition once.
This is easily dealt with using a composite key on a joining table.
A final note on the cost of storage for indexes.
This is an implementation detail - I'll take PostgreSQL and MySQL.
All of PostgreSQL's indexes are secondary indexes, i.e.:
All indexes in PostgreSQL are secondary indexes, meaning that each
index is stored separately from the table's main data area (which is
called the table's heap in PostgreSQL terminology). This means that in
an ordinary index scan, each row retrieval requires fetching data from
both the index and the heap. Furthermore, while the index entries that
match a given indexable WHERE condition are usually close together in
the index, the table rows they reference might be anywhere in the
heap.
Now, there are such things as index only scans which mean that no secondary search has to be performed, if all of the data is in the index itself - this effectively means that the PK in this case is, effectively the table and the actual heap table is (in a certain sense) "baggage".
Finally, PostgreSQL doesn't have clustered indexes (as normally understood) - see here for discussion - it does, but only until the table is updated - see link.
MySQL on the other hand always has a clustered index on the primary key(*) which means no extra storage - if both fields of a joining table are the key, then there is no "baggage" - see here:
(*) MySQL will automatically create a PK "behind the scenes" even if the dev/DBA does not - see link.
Accessing a row through the clustered index is fast because the index
search leads directly to the page that contains the row data. If a
table is large, the clustered index architecture often saves a disk
I/O operation when compared to storage organizations that store row
data using a different page from the index record.
For other systems, you'll have to do the research - see here - interestingly MS SQL Server uses clustered indexes (optional) whereas Oracle doesn't - but it has IOTs (Index Organised Tables) - I'll leave it up to the reader to investigate all these other systems' various mechanisms of storage organisation.