My guess is, that because I have an aggregation, the server has to process all rows anyways, therefore the impact is not that high.
Speaking from a SQL Server perspective, it depends. Here is an overview of what it depends on, and why:
Row Goals
Adding a top-level TOP (n) clause (with or without ORDER BY) has the same row goal effect as if a FAST (n) query hint had been specified. A row goal causes the optimizer to estimate plan costs on the basis of returning n rows quickly.
A small row goal therefore favours serial execution using non-blocking (pipelined) operators like (sort-free) merge or nested loops join, and semi-blocking (per group) operators like stream aggregate, over fully blocking operators like sort and eager hash distinct.
Combination operators, like hash join (which is blocking on its hash table build input, and pipelined on its probe input) may be chosen if the build input is expected to be small, and the build input is not expected to rebind much (or at all).
Pipelined execution
Where the logic of the query allows it, and suitable indexes exist, the optimizer may well be able to find a fully pipelined (or perhaps, semi-blocking) execution plan. A semi-blocking plan that blocks per group is potentially just fine, so long as the groups are small.
Even with optimal indexing, in some cases, it may be necessary to express the query using just the right syntax, perhaps also using various query and table hints, to obtain the most pipelined execution plan possible. It can be very tricky to achieve in all but the simplest cases.
A pipelined/semi-blocking plan means the SqlDataReader.Read() can fetch the first and subsequent rows with minimal latency. Essentially, both the C# code and the SQL Server execution engine are streaming rows. This is the case where specifying TOP (n) will make the most difference.
Default strategy
Where TOP (n) is not specified, the query optimizer targets total execution time for the full potential set of rows the query is expected to produce. This change in optimization goal tends to favour parallelism, fully blocking sorts & eager hash aggregation, and partially-blocking hash joins, for example. This would typically produce the full set significantly quicker than running a pipelined/semi-blocking plan (if available) to its final conclusion.
Where one or more blocking operators appears in a plan, the time-to-first-row may be a sizeable fraction of the potential overall execution time. This means the first SqlDataReader.Read() call will block for a long time. Stopping the DataReader after n rows are received by the client will have a relatively minor effect on elapsed time in this case, because the majority of the SQL Server work is already one before the first row becomes available.
Conclusion
How much effect adding TOP (n) has therefore depends at least on:
- There being a pipelined execution plan solution (even in principle)
- Suitable access methods (indexing)
- Query syntax and optimizer features / limitations
- The skill level and experience of the query developer
Example
Using the ContosoRetailDW sample dataset, where table FactOnlineSales has 12,627,600 rows. A query based on the template in the question is:
SELECT
FOS.ProductKey,
DS.StoreKey,
SUM(FOS.SalesAmount)
FROM dbo.DimStore AS DS
JOIN dbo.FactOnlineSales AS FOS
ON DS.StoreKey = FOS.StoreKey
GROUP BY
FOS.ProductKey,
DS.StoreKey
ORDER BY
FOS.ProductKey,
DS.StoreKey;
Adding a useful index:
CREATE INDEX i
ON dbo.FactOnlineSales
(ProductKey, StoreKey)
INCLUDE
(SalesAmount);
The execution plan is:
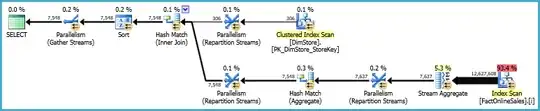
This runs for 1650ms. Notice the sort and hashing operations.
With TOP (n)
Choosing n = 50 arbitrarily, the query is now:
SELECT TOP (50)
FOS.ProductKey,
DS.StoreKey,
SUM(FOS.SalesAmount)
FROM dbo.DimStore AS DS
JOIN dbo.FactOnlineSales AS FOS
ON DS.StoreKey = FOS.StoreKey
GROUP BY
FOS.ProductKey,
DS.StoreKey
ORDER BY
FOS.ProductKey,
DS.StoreKey;
and the execution plan:
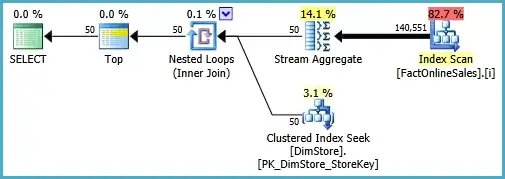
This runs for 57ms using pipelined iterators and per-group semi-blocking stream aggregate (instead of blocking eager hash).
Related question: How (and why) does TOP impact an execution plan?

