If you were using a person's name as a primary key and their name changed you would need to change the primary key. This is what ON UPDATE CASCADE is used for since it essentially cascades the change down to all related tables that have foreign-key relationships to the primary key.
For example:
USE tempdb;
GO
CREATE TABLE dbo.People
(
PersonKey VARCHAR(200) NOT NULL
CONSTRAINT PK_People
PRIMARY KEY CLUSTERED
, BirthDate DATE NULL
) ON [PRIMARY];
CREATE TABLE dbo.PeopleAKA
(
PersonAKAKey VARCHAR(200) NOT NULL
CONSTRAINT PK_PeopleAKA
PRIMARY KEY CLUSTERED
, PersonKey VARCHAR(200) NOT NULL
CONSTRAINT FK_PeopleAKA_People
FOREIGN KEY REFERENCES dbo.People(PersonKey)
ON UPDATE CASCADE
) ON [PRIMARY];
INSERT INTO dbo.People(PersonKey, BirthDate)
VALUES ('Joe Black', '1776-01-01');
INSERT INTO dbo.PeopleAKA(PersonAKAKey, PersonKey)
VALUES ('Death', 'Joe Black');
A SELECT against both tables:
SELECT *
FROM dbo.People p
INNER JOIN dbo.PeopleAKA pa ON p.PersonKey = pa.PersonKey;
Returns:
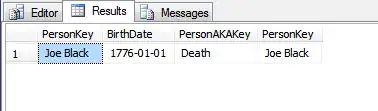
If we update the PersonKey column, and re-run the SELECT:
UPDATE dbo.People
SET PersonKey = 'Mr Joe Black'
WHERE PersonKey = 'Joe Black';
SELECT *
FROM dbo.People p
INNER JOIN dbo.PeopleAKA pa ON p.PersonKey = pa.PersonKey;
we see:
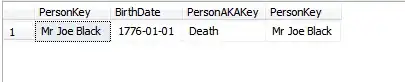
Looking at the plan for the above UPDATE statement, we clearly see both tables are updated by a single update statement by virtue of the foreign key defined as ON UPDATE CASCADE:
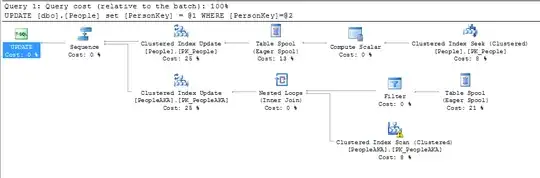 click the image above to see it in more clarity
click the image above to see it in more clarity
Finally, we'll cleanup our temporary tables:
DROP TABLE dbo.PeopleAKA;
DROP TABLE dbo.People;
The preferred1 way to do this using surrogate keys would be:
USE tempdb;
GO
CREATE TABLE dbo.People
(
PersonID INT NOT NULL IDENTITY(1,1)
CONSTRAINT PK_People
PRIMARY KEY CLUSTERED
, PersonName VARCHAR(200) NOT NULL
, BirthDate DATE NULL
) ON [PRIMARY];
CREATE TABLE dbo.PeopleAKA
(
PersonAKAID INT NOT NULL IDENTITY(1,1)
CONSTRAINT PK_PeopleAKA
PRIMARY KEY CLUSTERED
, PersonAKAName VARCHAR(200) NOT NULL
, PersonID INT NOT NULL
CONSTRAINT FK_PeopleAKA_People
FOREIGN KEY REFERENCES dbo.People(PersonID)
ON UPDATE CASCADE
) ON [PRIMARY];
INSERT INTO dbo.People(PersonName, BirthDate)
VALUES ('Joe Black', '1776-01-01');
INSERT INTO dbo.PeopleAKA(PersonID, PersonAKAName)
VALUES (1, 'Death');
SELECT *
FROM dbo.People p
INNER JOIN dbo.PeopleAKA pa ON p.PersonID = pa.PersonID;
UPDATE dbo.People
SET PersonName = 'Mr Joe Black'
WHERE PersonID = 1;
For completeness, the plan for the update statement is very simple, and shows one advantage to surrogate keys, namely only a single row needs to be updated as opposed to every row containing the key in a natural-key scenario:

SELECT *
FROM dbo.People p
INNER JOIN dbo.PeopleAKA pa ON p.PersonID = pa.PersonID;
DROP TABLE dbo.PeopleAKA;
DROP TABLE dbo.People;
The output from the two SELECT statements above are:
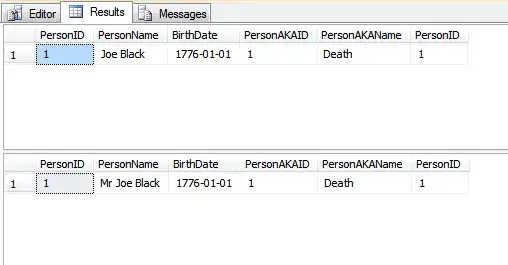
Essentially, the outcome is approximately the same. One major difference is the wide natural key is not repeated in every table where the foreign key occurs. In my example, I'm using a VARCHAR(200) column to hold the person's name, which necessitates using a VARCHAR(200) everywhere. If there are a lot of rows and a lot of tables containing the foreign key, that will add up to a lot of wasted memory. Note, I'm not talking about disk space being wasted since most people say disk space is so cheap as to be essentially free. Memory, however, is expensive and deserves to be cherished. Using a 4-byte integer for the key will save a large amount of memory when you consider the average name length of around 15 characters.
Tangential to the question about how and why keys can change is the question about why to choose natural keys over surrogate keys, which is an interesting and perhaps more important question, especially where performance is a design-goal. See my question here about that.
1 - http://weblogs.sqlteam.com/mladenp/archive/2009/10/06/Why-I-prefer-surrogate-keys-instead-of-natural-keys-in.aspx




