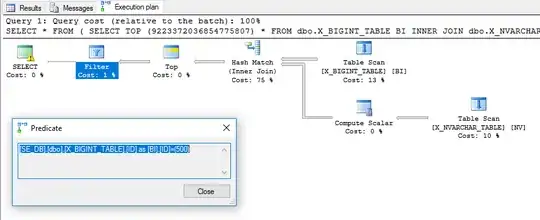
SqlZim already gave you a good method to avoid the error in his answer. However, in the question and in comments you seem curious as to why one query throws an error and the other does not. I am able to reproduce your issue:
CREATE TABLE dbo.X_BIGINT_TABLE (ID BIGINT NOT NULL);
INSERT INTO dbo.X_BIGINT_TABLE WITH (TABLOCK)
SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM master..spt_values;
CREATE TABLE dbo.X_NVARCHAR_TABLE (ID_NV NVARCHAR(10) NOT NULL);
INSERT INTO dbo.X_NVARCHAR_TABLE WITH (TABLOCK)
SELECT TOP (999) CAST(ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS NVARCHAR(10))
FROM master..spt_values
UNION ALL
SELECT 'ZOLTAN';
This query works fine:
SELECT *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE ISNUMERIC(NV.ID_NV) = 1;
This query throws an error:
SELECT *
FROM (
SELECT *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE ISNUMERIC(NV.ID_NV) = 1
) ZZ
WHERE ZZ.ID = 500;
Msg 8114, Level 16, State 5, Line 25
Error converting data type nvarchar to bigint.
The SQL Server query optimizer can reorder elements of a query as it sees fit to try to find a query plan with a good enough estimated cost, as long as the changes do not affect the final results of the query. To illustrate the concept lets walk through one possible way the second query can be refactored. To be clear, this is not the actual step-by-step process that the query optimizer goes through for this example. Start with the query:
SELECT *
FROM (
SELECT *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE ISNUMERIC(NV.ID_NV) = 1
) ZZ
WHERE ZZ.ID = 500;
Push down the predicate:
SELECT *
FROM (
SELECT *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE BI.ID = 500 AND ISNUMERIC(NV.ID_NV) = 1
) ZZ;
The derived table is no longer needed so get rid of that:
SELECT *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE BI.ID = 500 AND ISNUMERIC(NV.ID_NV) = 1
We know that BI.ID = NV.ID_NV so we can apply the filter on Z.ID to NV.ID_NV as well:
SELECT *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE BI.ID = 500 AND ISNUMERIC(NV.ID_NV) = 1 AND NV.ID_NV = 500
The join no longer needs to be implemented as INNER JOIN because we are filtering down to a single value for both join columns. We can rewrite as a CROSS JOIN:
SELECT *
FROM
(
SELECT *
FROM dbo.X_BIGINT_TABLE BI
WHERE BI.ID = 500
)
CROSS JOIN
(
SELECT *
FROM dbo.X_NVARCHAR_TABLE NV
WHERE ISNUMERIC(NV.ID_NV) = 1 AND NV.ID_NV = 500
);
If we look at the query plan for the second query we can tell that the end result is very similar to the final transformed query:
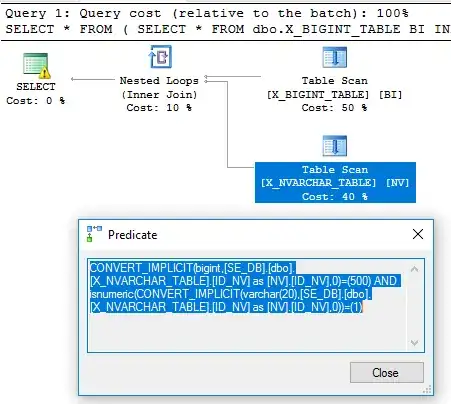
Here is the text of the filter predicate for reference:
CONVERT_IMPLICIT(bigint,[SE_DB].[dbo].[X_NVARCHAR_TABLE].[ID_NV] as [NV].[ID_NV],0)=(500)
AND isnumeric(CONVERT_IMPLICIT(varchar(20),[SE_DB].[dbo].[X_NVARCHAR_TABLE].[ID_NV] as [NV].[ID_NV],0))=(1)
If SQL Server evaluates the CONVERT_IMPLICIT part of the predicate before the isnumeric part then we get an error.
As a general rule, avoid relying on implied order of operations when writing SQL queries. You may have a query that works well today but starts to throw errors if data is added to the table or if a different query plan is chosen. There are, of course, exceptions (kind of). In practice, you will usually see the different parts of a CASE statement to evaluate in the order that you've written them, but even then it's possible to get errors that you weren't expecting. You can also add a superfluous TOP to parts of your query to encourage a certain order of operations. Consider the following query:
SELECT *
FROM (
SELECT TOP (9223372036854775807) *
FROM dbo.X_BIGINT_TABLE BI
INNER JOIN dbo.X_NVARCHAR_TABLE NV ON BI.ID = NV.ID_NV
WHERE ISNUMERIC(NV.ID_NV) = 1
) ZZ
WHERE ZZ.ID = 500;
You and I know that the TOP will not change the results of the query, However, there is not a guarantee to the optimizer that the derived table won't return more than 9223372036854775807 rows so it must evaluate the TOP. Technically, in that query we ask for the first 9223372036854775807 rows and then we want to filter out rows with an ID different from 500. Pushing the ID = 500 predicate down to the derived table could change the results so SQL Server will not do that. In this example, the query executes without an error and the filtering is done at the very end: