Since a timestamp is a 8 bytes and a datetime is 8 bytes, there will be no appreciable difference between the two in terms of performance.
Adding an appropriate index will make a much larger difference in the work required for SQL Server to fulfill the SOLR query.
To test this, I've created the following minimally complete verifiable example:
USE tempdb;
GO
IF OBJECT_ID(N'dbo.Books', N'U') IS NOT NULL
DROP TABLE dbo.Books;
CREATE TABLE dbo.Books
(
BookID int NOT NULL IDENTITY(1,1)
CONSTRAINT PK_Books
PRIMARY KEY CLUSTERED
, Book_Collection varchar(30) NOT NULL
, updated_on datetime NOT NULL
, Pad varchar(100) NOT NULL
) ON [PRIMARY];
;WITH Nums AS (
SELECT v.Num
FROM (VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9))v(Num)
)
INSERT INTO dbo.Books (Book_Collection, updated_on, Pad)
SELECT v1.Num + v2.num * 10 + v2.num * 100
, DATEADD(MINUTE, 0 - (v2.Num * 10 + v3.Num * 100), GETDATE())
, CONVERT(varchar(100), CRYPT_GEN_RANDOM(100))
FROM Nums v1
CROSS JOIN Nums v2
CROSS JOIN Nums v3
CROSS JOIN Nums v4;
GO
The above inserts 10,000 rows across 1,000 book_collection values, with varying updated_on values.
My example SOLR query:
SELECT b.Book_Collection
FROM dbo.Books b
GROUP BY b.Book_Collection
HAVING MAX(b.updated_on) > DATEADD(MINUTE, 0 - 3, GETDATE())
The plan for this query:
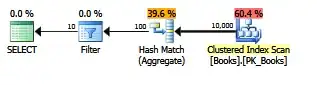
Stats for this query:
SQL Server parse and compile time:
CPU time = 16 ms, elapsed time = 26 ms.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, >read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Books'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 57 ms.
If we add this index, and re-run the same query:
CREATE INDEX IX_Books_Collection
ON dbo.Books (Book_Collection, updated_on);
We see the following plan and statistics:
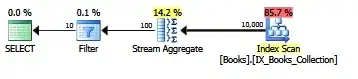
SQL Server parse and compile time:
CPU time = 8 ms, elapsed time = 8 ms.
Table 'Books'. Scan count 1, logical reads 33, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 6 ms.
I/O is substantially reduced, as is CPU time and elapsed time. Clearly, adding a helpful index will make the query more efficient.
If we re-create the experiment using a timestamp column in place of the datetime column, we see very similar results:
IF OBJECT_ID(N'dbo.Books', N'U') IS NOT NULL
DROP TABLE dbo.Books;
CREATE TABLE dbo.Books
(
BookID int NOT NULL IDENTITY(1,1)
CONSTRAINT PK_Books
PRIMARY KEY CLUSTERED
, Book_Collection varchar(30) NOT NULL
, updated_on timestamp NOT NULL
, Pad varchar(100) NOT NULL
) ON [PRIMARY];
;WITH Nums AS (
SELECT v.Num
FROM (VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9))v(Num)
)
INSERT INTO dbo.Books (Book_Collection, Pad)
SELECT v1.Num + v2.num * 10 + v2.num * 100, CONVERT(varchar(100), CRYPT_GEN_RANDOM(100))
FROM Nums v1
CROSS JOIN Nums v2
CROSS JOIN Nums v3
CROSS JOIN Nums v4;
GO
Stats for the query without the index in place:
SQL Server parse and compile time:
CPU time = 15 ms, elapsed time = 19 ms.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Books'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 3 ms.
And with the index in place:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
Table 'Books'. Scan count 1, logical reads 33, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.



