The following code creates a view to provide access to the side-effecting function, CRYPT_GEN_RANDOM. The function calls the view numerous times getting a single byte from CYRPT_GEN_RANDOM for each call.
DROP FUNCTION IF EXISTS dbo.gen_ran_tvf;
DROP VIEW IF EXISTS dbo.gen_ran_view;
GO
CREATE VIEW dbo.gen_ran_view
WITH SCHEMABINDING
AS
SELECT cgr = CONVERT(int, CRYPT_GEN_RANDOM(1));
GO
CREATE FUNCTION dbo.gen_ran_tvf
(
@digits int
, @randomizer int
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN (
WITH nums AS (
SELECT n = CONVERT(int, v.n)
FROM (VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9))v(n)
)
, digits AS (
SELECT TOP(@digits)
v.cgr
FROM dbo.gen_ran_view v
CROSS JOIN nums n1
CROSS JOIN nums n2
)
SELECT
t = LEFT(
(
SELECT '' + digits.cgr
FROM digits
FOR XML PATH('')
)
, @digits)
, r = @randomizer
);
GO
The function itself is a schema-bound table-valued-function that can be "inlined" by the SQL Server query optimizer, and as a result is about as fast as you can get for this type of operation.
I created a test table and populated it with 1,000,000 rows:
DROP TABLE IF EXISTS dbo.SampleData;
GO
CREATE TABLE dbo.SampleData
(
SampleDataID int NOT NULL
CONSTRAINT PK_SampleData
PRIMARY KEY
CLUSTERED
IDENTITY(1,1)
, SomeVal varchar(50) NOT NULL
);
GO
TRUNCATE TABLE dbo.SampleData;
GO
INSERT INTO dbo.SampleData (SomeVal)
SELECT TOP(1000000) CONVERT(varchar(50), '')
FROM sys.syscolumns c1
, sys.syscolumns c2;
GO
This is how you might expect to use the TVF to update the SampleData table:
UPDATE dbo.SampleData
SET SomeVal = tvf.t
FROM dbo.SampleData sd
CROSS APPLY dbo.gen_ran_tvf(50, sd.SampleDataID) tvf
However, with a large number of rows, the resulting execution plan uses a performance table spool to generate a single row from the TVF. This results in every row having the same value, which is not the desired state.
For this particular setup, if you only insert 57 rows into the table, and run the above statement, you do see random values for each row since the table spool is no longer present, and the query optimizer chooses to execute the TVF once for each row in SampleData.
If you run on SQL Server 2016 or newer, you can use a new table hint, NO_PERFORMANCE_SPOOL, to ensure this "optimization" is never used. When you combine that hint with the join-order-enforcing hint, FORCE ORDER, the result is random rows for every row in the table, no matter how many rows are present.
So, the update statement becomes:
UPDATE dbo.SampleData
SET SomeVal = tvf.t
FROM dbo.SampleData sd
CROSS APPLY dbo.gen_ran_tvf(50, sd.SampleDataID) tvf
OPTION (
NO_PERFORMANCE_SPOOL
, FORCE ORDER
);
GO
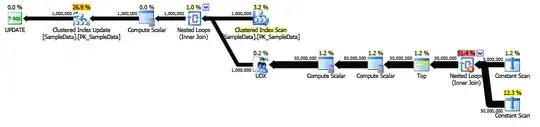
The "actual" execution plan:
Looking at the table:
SELECT *
FROM dbo.SampleData;
We see:
╔══════════════╦════════════════════════════════════════════════════╗
║ SampleDataID ║ SomeVal ║
╠══════════════╬════════════════════════════════════════════════════╣
║ 1 ║ 13112011187125181161243421302232222710240208203146 ║
║ 2 ║ 46314918617612853143741876746110662154749221200135 ║
║ 3 ║ 51061817319197421023124056174411660871198014321011 ║
║ 4 ║ 42184243211535022623816320713413918322511811717948 ║
║ 5 ║ 50931761021417838201791946726229222231676112631621 ║
║ 6 ║ 13588442531751073017338155821851591207315016221382 ║
║ 7 ║ 12418133401459429211173481131611316869160118221209 ║
║ 8 ║ 82271435818112225210622167252113138163226124182352 ║
║ 9 ║ 75220220124661172206422425299201988022810670231532 ║
║ 10 ║ 21610776198239186174931291616122930332049222921229 ║
║ 11 ║ 22811311396795182941996034109261472352503620625436 ║
║ 12 ║ 74612472525863716112125157233126171220494114848272 ║
║ 13 ║ 25119215323633306520710920720911421423524322717016 ║
║ 14 ║ 57250150114123725014912523398921624261693927878515 ║
║ 15 ║ 13116129240304813115918225022257130174017136111245 ║
...
║ 660731 ║ 23916221915121421617721762187898720350232178132462 ║
║ 660732 ║ 17016020013213211911920940141102196558714414847243 ║
║ 660733 ║ 16108202204200984770211104216131122159591931201861 ║
║ 660734 ║ 15524112614417119114811316419015619112023520711342 ║
╚══════════════╩════════════════════════════════════════════════════╝
On my old, slow workstation, updating 1,000,000 rows with this TVF takes around 40 seconds to complete.
Since we are "gluing" together individual sets of numbers in the range of 0 to 255, there will be a higher number of occurrences of the numbers 1 and 2 than of the other numbers; however since you're using this to obfuscate data instead of encrypting it, I don't think that will be a deal-breaking problem.
