Leaving aside the fragmentation bogeyeman (it doesn't really matter when doing singleton lookups), the main difference is that an RID specifies the exact page a row is on, while with a Key Lookup you traverse the non-leaf levels of the clustered index to find the target page. Aaron Bertrand did some tests on this in Is a RID Lookup faster than a Key Lookup?
However, Heaps can have forwarded fetches (or records) in them, in which case multiple logical IOs are required to find the target row.
I blogged about this recently, and I'm reproducing the content here to avoid a comment answer.
CREATE TABLE el_heapo
(
id INT IDENTITY,
date_fudge DATE,
stuffing VARCHAR(3000)
);
INSERT dbo.el_heapo WITH (TABLOCKX)
( date_fudge, stuffing )
SELECT DATEADD(HOUR, x.n, GETDATE()), REPLICATE('a', 1000)
FROM (
SELECT TOP (1000 * 1000)
ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2
) AS x (n)
CREATE NONCLUSTERED INDEX ix_heapo ON dbo.el_heapo (date_fudge);
We can look at the table with sp_BlitzIndex
EXEC master.dbo.sp_BlitzIndex @DatabaseName = N'Crap',
@SchemaName = 'dbo',
@TableName = 'el_heapo';

This query will produce bookmark lookups.
SELECT *
FROM dbo.el_heapo AS eh
WHERE eh.date_fudge BETWEEN '2018-09-01' AND '2019-09-01'
AND 1 = (SELECT 1)
OPTION(MAXDOP 1);
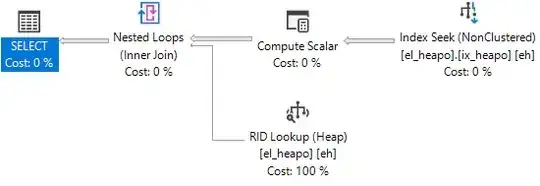
Now we can cause some forwarded records to occur:
UPDATE eh
SET eh.stuffing = REPLICATE('z', 3000)
FROM dbo.el_heapo AS eh
WHERE eh.date_fudge BETWEEN '2018-09-01' AND '2019-09-01'
OPTION(MAXDOP 1)
BlitzIndex will show them to us:

And if we re-run the lookup query:

Profiler will show a difference as well:





