Why?
Saying it in short. Because of HASH hint shots to optimizer's leg and optimizer itself shots to the other. Being shot to both optimizer can't cross the finish line.
To better illustrate what is going on, let's rewrite problematic query to join two VALUES and to use merge algorithm instead
DECLARE @id1 int = 101, @id3 int = 103;
SELECT *
FROM (VALUES (@id1)) p([Id])
FULL MERGE JOIN (VALUES (@id1), (@id3)) d([Id]) ON d.[Id] = p.[Id];
Execution plan of this query is simple. There is the Merge Join operator with two Constant Scan inputs.
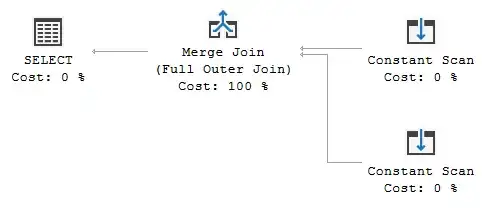
These two Constant Scans are different to optimizer though.

The one representing single-row input has column name prefixed with Expr, whereas the other representing multiple-rows input has column name prefixed with Union. Data from multiple-rows Constant Scan is accessed in the Merge Join predicates a kind of "by reference" ([Union1001]), whereas single-row Constant Scan data is accessed a kind of "by value" (see that @id1 is substituted instead of [Expr1000]).
This "by reference"→"by value" substitution is the result of scalar mapping performed at early optimization stages.
One can see (using trace flag 8606) that in the Input Tree join predicate is [Union1001] = [Expr1000]
*** Input Tree: ***
...
LogOp_FullOuterJoin
...
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL: Union1001
ScaOp_Identifier COL: Expr1000
...
but then in the Simplified Tree it becomes [Union1001] = @id1
*** Simplified Tree: ***
LogOp_FullOuterJoin
...
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL: Union1001
ScaOp_Identifier COL: @id1
Scalar mapping is the part of projection pulling logic and actually performed before simplification stage is entered.
One may did noticed earlier, that Merge Join node has only residual predicate and no join equality predicate. This is because of join equality predicate has been eliminated by scalar mapping. The [Union1001] = @id1 is equality predicate, but it can not serve as a join equality predicate. To be such it has to reference columns from both inputs, but @id1 is variable and not a column.
So, being equijoin ON d.[Id] = p.[Id] originally, the query transformed to non-equijoin (which is special case, and because of that, by the way, optimizer did not introduced sorting below Merge Join for the non-sorted Constant Scan inputs). Fortunately, in case of merge algorithm optimizer has such non-equijoin alternative.
In case of using hash algorithm non-equijoin alternative does not exists, and so, join equality predicate elimination causes optimizer to fail later on.
Is there a way (besides putting parameter into temporary table) to
make it work using hash algorithm?
There is no trace flag(*) that prevents scalar mapping, neither query lever nor session level nor start-up. And there is no optimization rule that can be turned off to prevent it, because of it is not performed by a rule.
I was only able to execute problematic query by setting breakpoint in the COptExpr::PexprMapScalar routine
and modifying value of the eax register after call to ScaOp_Identifier::ClassNo to make SQL Server think that second operand of ScaOp_Comp is not identifier.
Here is the Simplified Tree of the problematic query posted in the question
*** Simplified Tree: ***
LogOp_FullOuterJoin
LogOp_ConstTableGet (1) COL: Expr1000
ScaOp_Identifier COL: @id1
LogOp_Get TBL: #data(alias TBL: d)
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [d].Id
ScaOp_Identifier COL: Expr1000
*******************
and here is its plan obtained.
It has little sense actually, because of obtained plan cost is 0.0210675 units, whereas running query without HASH hint leads to execution plan with Merge Join (notice no sorting below Merge Join again)
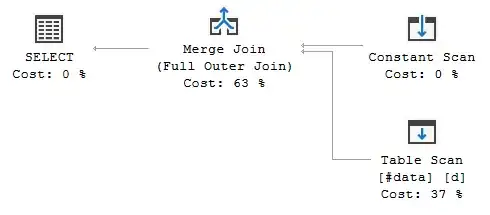
costing 0.0088948 units.
(*) There may exist a combination of trace flags. I think it doesn't though, but I didn't explored all code paths, so I don't know it for certainty.




