Short answer
From a logical perspective, there are no inherent disadvantages to a composite key. It exists. If it is required to maintain uniqueness/data integrity, you must use it.
From a physical implementation perspective, a composite key may create fragmentation of the b-tree and clustered index (if used/supported) as inserts are not guaranteed to append to the end of the table. Most commercial database engines are pretty good about handling/managing fragmentation (and some always append new rows to new pages) so this shouldn't be your reason for choosing one over another except in a very narrow set of circumstances.
Longer Answer
So let's back up a moment because I think there's a crucial thing about primary keys that's missed by most practitioners:
A primary key must enforce uniqueness of the data.
An id column does not enforce uniqueness as it is system-generated, not from the data.
So it doesn't make sense to tack an id on every entity at the beginning of data modeling because it will prevent you from understanding the actual structure of the data. We can apply id columns later, once the actual keys are known. The id will be the surrogate for the prior primary key, and that key will become an alternate key.
So I can see from your diagram that you are at least aware of that later fact for Function, but have not applied that to Area or Department.
So let's begin by removing the row identifiers from the equation. This is what you would have:

At this point it would be natural to ask:
- Is a
function independent of all departments?
- Can more than one
department fulfill the same function?
In the first case, our model would then become:
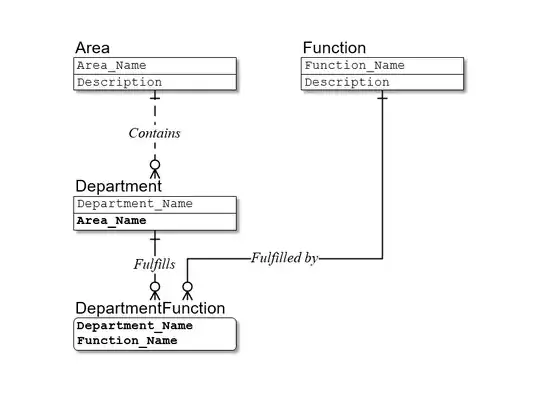
But if the second held true, then the model instead would be:
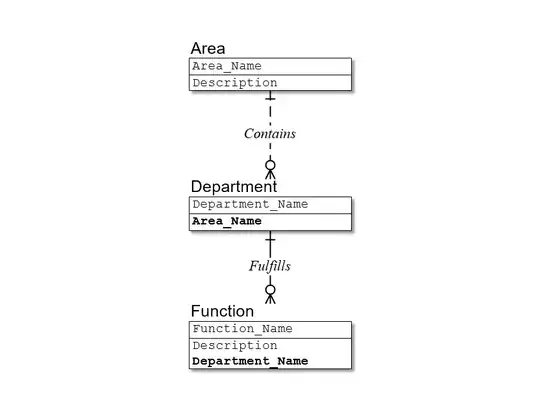
So you can see, there is a lot of work to be done before we start thinking about whether or not to replace the existing primary key with a surrogate.
We may decide that Area_Name is too wide to be useful in practice. We can make that an alternate key and substitute either a human-readable code/short name (preferred) or system-generated integer (if you really must). We could decide similarly for Department_Name.
So let's implement the second model, replacing the wide keys with surrogates:
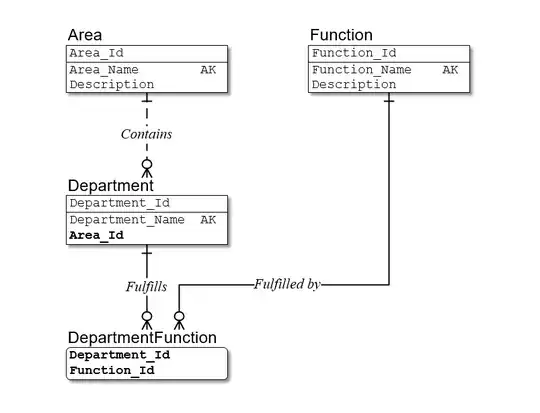
In this case, DepartmentFunction has the key (Department_Id,Function_Id) which is:
- Compact
- Preserves the relation to
Department, which may be needed for integrity later in the data model
So there is no compelling reason to replace it.
One thing I would stress is that only use integer surrogates as a last resort. If there is an shorthand/code that can be used this is preferable as:
- It is human readable
- May already be in common use
- May reduce the number of joins required
- May be more compact if the length is less than 4
- Reduce data errors (integer columns get swapped more than some would like to admit)




