We have setup a streaming replication on Postgres 13 and it all works fine. Current setup is as follows.
We have one Primary Postgres and one Secondary Postgres connected via streaming replication. This replication and cluster management of failover is managed by Patroni. We have PGBouncer for connection pooling and it is currently connected to PG Master. This works fine without issues.
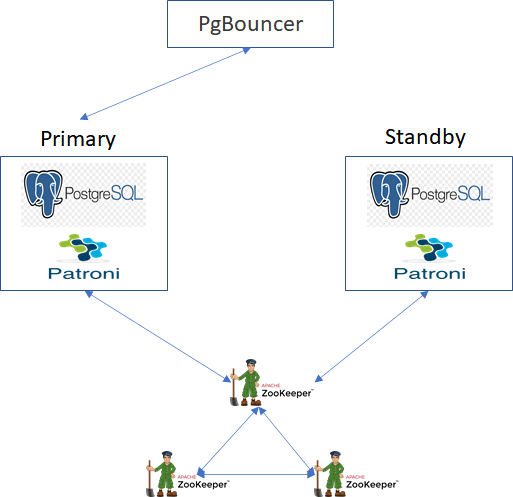
We wanted to use the secondary postgres for read purposes to reduce the read load on Primary. So we wanted to introduce PGPool in the eco system to get benefit of read/write splits. Couple of articles suggested that we could use both PGBouncer and PgPool together to get better results from both tools (https://scalegrid.io/blog/postgresql-connection-pooling-part-4-pgbouncer-vs-pgpool/). So now our setup adds PgPool-II between PgBouncer and PG with connection pooling disabled.
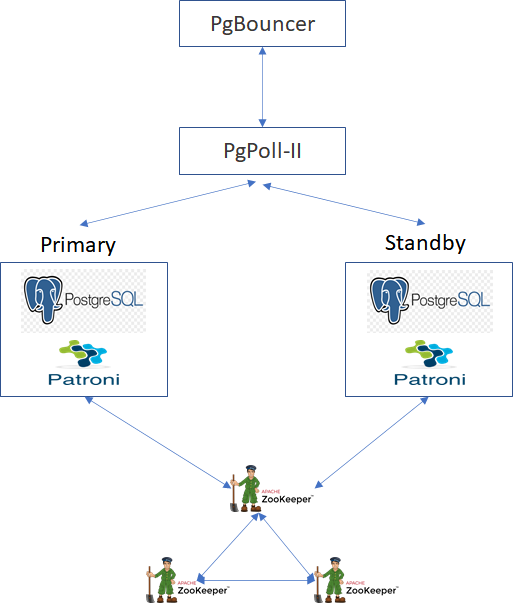
This setup also works fine. However I am not able to understand about connection pooling. I could see many connections in pgpool when i do SHOW POOL_POOLS;
- Who is holding on to the connections for connection pooling ? PgBouncer/PgPool ?
- Why I see connections when I issue command show pool_pools in pgpool when connection pooling is disabled.
- Is this setup right and scalable? What configurations I need to change to get better of both tools ?