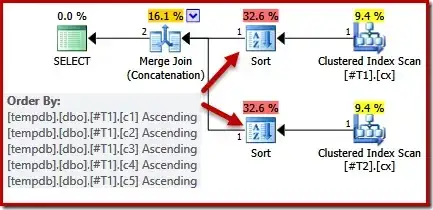
I have a very simple query where I use a UNION ALL + ORDER BY over two queries that return pre-sorted data from respective indexes. For some reason, SQL will not use a Merge Join (Concatenation) for this, but a "normal" Concatenation, followed by a Sort. What could be the reason for that?
Here's a complete repro sample. (The INDEX hints are required to make SQL Server use the index despite the low number of rows in the table.)
CREATE TABLE T1(
SequenceNumber bigint IDENTITY NOT NULL,
TenantId uniqueidentifier NOT NULL,
Object1Id uniqueidentifier NOT NULL,
Payload nvarchar(max) NOT NULL,
OtherNumber bigint NOT NULL,
CONSTRAINT PK_T1 PRIMARY KEY CLUSTERED (TenantId,SequenceNumber ASC)
)
CREATE INDEX IX_TenantId_Object1Id_OtherNumber ON T1(TenantId, Object1Id, OtherNumber)
CREATE TABLE T2(
SequenceNumber bigint IDENTITY NOT NULL,
TenantId uniqueidentifier NOT NULL,
Object2Id uniqueidentifier NOT NULL,
Payload nvarchar(max) NOT NULL,
OtherNumber bigint NOT NULL,
CONSTRAINT PK_T2 PRIMARY KEY CLUSTERED (TenantId,SequenceNumber ASC)
)
CREATE INDEX IX_TenantId_Object2Id_OtherNumber ON T2(TenantId, Object2Id, OtherNumber)
DECLARE @tenantId UNIQUEIDENTIFIER = NEWID()
DECLARE @object1Id UNIQUEIDENTIFIER = NEWID()
DECLARE @object2Id UNIQUEIDENTIFIER = NEWID()
SELECT OtherNumber, Payload FROM T1 WITH (INDEX(IX_TenantId_Object1Id_OtherNumber)) WHERE TenantId = @tenantId AND Object1Id = @object1Id
UNION ALL
SELECT OtherNumber, Payload FROM T2 WITH (INDEX(IX_TenantId_Object2Id_OtherNumber)) WHERE TenantId = @tenantId AND Object2Id = @object2Id
ORDER BY OtherNumber
DROP TABLE T1
DROP TABLE T2
And this is a screenshot of the execution plan:

When I add the MERGE UNION option, SQL Server will explicitly pre-sort the individual query results (on OtherNumber and Payload, for some reason).
Now an interesting twist: When I add a UNIQUE constraint on the OtherNumber columns, SQL Server will suddenly choose the Merge Join (Concatenation) operator. Why?
I've tested this both locally on SQL Server 2016 and on Azure SQL.