how does row versioning impact the size of a non-clustered columnstore index?
This is a very open-ended question, but you are right that compressed segments are immutable.
The details of the versioning implementation for columnstore are largely undocumented, even in the various academic columnstore papers published by Microsoft.
Versioning and visibility
Essentially, all the b-tree elements of the columnstore implementation are versioned. This includes the delta store(s), delete bitmaps (bitmap in memory, versioned b-tree on disk), and the delete buffer only used with secondary columnstore (see below).
Various implementation details ensure that versions remain accessible as long as they might be needed. For example, a delta store transitioned to compressed format by the tuple mover leaves the delta store behind in TOMBSTONE status until all versioning transactions that might need those versions have ended.
I don't recall exactly how SQL Server ensures compressed segments are checked for visibility. Probably the LOB storage is versioned as usual, meaning the entire LOB has a single row version at the root—there is no per-row versioning. The row group is created all at once, so the same visibility applies to all rows as a starting point.
SQL Server does not make it easy to see the LOB root details because many of the internal details and metadata e.g. for the segment directory are hidden.
My expectation is that your tests will show compressed segments of the same size regardless of versioning considerations, but delta stores, delete bitmaps, and delete buffers will be larger.
Versioning Performance
snapshot isolation inflicts a massive performance penalty on columnstore, but does not explain the internals.
The overhead for reading is higher on nonclustered columnstore than clustered columnstore.
The reasoning is that primary columnstore is targeted at applications where deletions are rare and scan performance is the highest priority. Even so, as the post you linked to demonstrates, there is still overhead caused by consulting the (versioned) delete bitmap and checking visibility.
Secondary columnstores are expected to experience frequent updates and deletes with lower scan activity. Secondary columnstores therefore prioritise deletion speed over scan performance.
Delete buffer
The additional issue for secondary columnstores is locating deleted secondary rows when they are not present in a delta store. Scanning the compressed segments for each deletion would be wildly inefficient, so secondary columnstores have a delete buffer as well as a delete bitmap.
The contents of the delete buffer are merged into the bitmap every so often by a background task that performs a single scan of the compressed segments. For more details, see How do nonclustered columnstore indexes in SQL Server handle linked updates and deletes with rowstore tables(either heap or clustered index tables)?.
Overheads
Batch processing is generally very efficient, so it doesn't take much additional overhead per row to produce a noticeable slowdown. Checking to see if a row is visible is not terribly expensive, but it isn't free either.
Call stacks
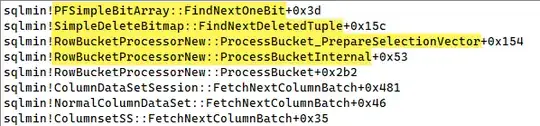
Some example call stacks reading from a nonclustered columnstore's delta store under SNAPSHOT isolation:
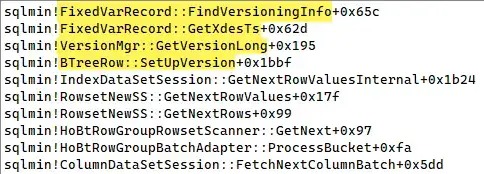
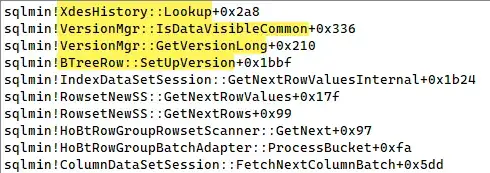
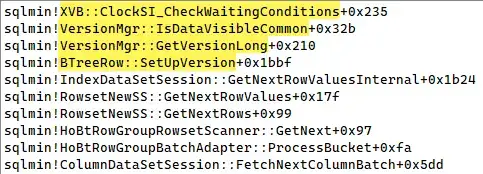
and one showing the delete bitmap being converted:
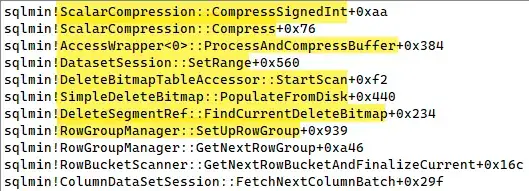
then used to eliminate a row from a batch:
Analysis
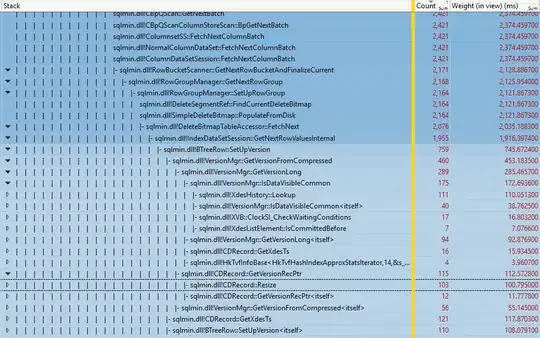
A Windows Performance Recorder and Analyzer session while the demo in the referenced post ran under SNAPSHOT isolation shows the expensive method calls, which you will recognise from the stack traces above:
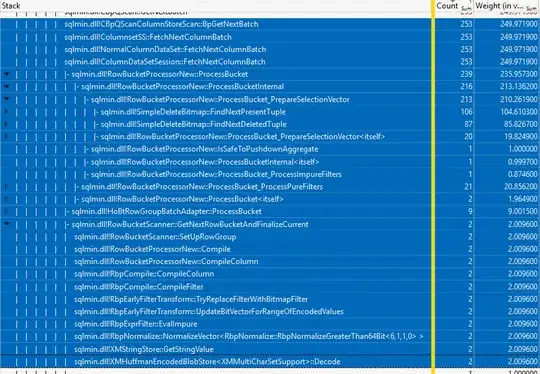
The same analysis for locking READ COMMITTED shows much shorter durations and no time spent in the versioning calls:
All that being as it is, performance is still very good under snapshot isolation. The scan of almost 100 million rows applying complex string predicates completes in 2.4s or so.
The same query under locking read committed completes in around 250ms, unless batch mode processing is disabled, in which case it takes almost 16 seconds.
Organised as a heap instead of clustered columnstore, the read committed run takes 14s (using batch mode on rowstore) and the snapshot isolation run takes 20s (also batch mode).






