The following is an alternative SQL Server 2008 R2 solution that is efficient when:
- There are relatively few
NULLs; and
- The right supporting indexes are available
The gaps-and-islands method may be faster if:
- The table is not too large (minimizing sorting costs); and
NULLs form a high proportion of the data.
Sample data and required indexes
CREATE TABLE dbo.Table1
(
[Target] char(1) NOT NULL,
[PollTime] datetime NOT NULL,
[Value] varchar(5) NULL,
PRIMARY KEY ([Target], [PollTime])
);
-- Optional helpful filtered index to find NULL rows in required order
CREATE UNIQUE INDEX fi1
ON dbo.Table1 ([Target], [PollTime])
INCLUDE (Value)
WHERE Value IS NULL;
-- Sample data
INSERT dbo.Table1
([Target], [PollTime], [Value])
VALUES
('A', '2013-12-13 13:31:44', '15.00'),
('A', '2013-12-13 13:32:44', '16.00'),
('A', '2013-12-13 13:33:44', '16.00'),
('A', '2013-12-13 13:34:44', NULL),
('A', '2013-12-13 13:35:44', NULL),
('A', '2013-12-13 13:36:44', '15.00'),
('B', '2013-12-21 05:29:34', '3.00'),
('B', '2013-12-21 05:30:34', NULL),
('B', '2013-12-21 05:31:34', NULL),
('B', '2013-12-21 05:32:34', NULL),
('B', '2013-12-21 05:33:34', '4.00'),
('B', '2013-12-21 05:34:34', NULL),
('B', '2013-12-21 05:35:34', NULL),
('B', '2013-12-21 05:36:34', '5.00');
Solution step 1:
-- Find start and end dates
SELECT
T1.[Target],
Calc.StartOrEnd,
Calc.PollTime,
GroupID = (ROW_NUMBER() OVER (ORDER BY T1.[Target], T1.PollTime) + 1) / 2
INTO #PartialResult
FROM dbo.Table1 AS T1
CROSS APPLY
(
-- Classify the outer NULL row as start, end or neither
SELECT TOP (1)
StartOrEnd.StartOrEnd,
StartOrEnd.PollTime
FROM
(
-- Start date test
SELECT
StartDate.StartOrEnd,
StartDate.PollTime,
StartDate.Value
FROM
(
SELECT TOP (1)
-- Looking for a Start date (S)
StartOrEnd = CONVERT(char(1), 'S'),
T1.PollTime,
T2.Value
FROM dbo.Table1 AS T2
WHERE
-- Find the previous row
T2.[Target] = T1.[Target]
AND T2.PollTime < T1.PollTime
ORDER BY
T2.PollTime DESC
) AS StartDate
WHERE
-- Is a Start date if the value isn't NULL
StartDate.Value IS NOT NULL
UNION ALL
-- End date test
SELECT
EndDate.StartOrEnd,
EndDate.PollTime,
EndDate.Value
FROM
(
SELECT TOP (1)
-- Looking for an End date (E)
StartOrEnd = CONVERT(char(1), 'E'),
T2.PollTime,
T2.Value
FROM dbo.Table1 AS T2
WHERE
-- Find the following row
T2.[Target] = T1.[Target]
AND T2.PollTime > T1.PollTime
ORDER BY
T2.PollTime ASC
) AS EndDate
WHERE
-- Is an end date if the value isn't NULL
EndDate.Value IS NOT NULL
) AS StartOrEnd
) AS Calc
WHERE
-- Outer row value is NULL
T1.value IS NULL;
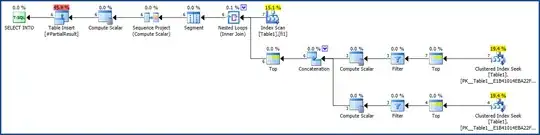
Solution step 2:
CREATE UNIQUE CLUSTERED INDEX cuq
ON #PartialResult (GroupID, [Target], StartOrEnd);
-- Special case: final end row
-- if the last row in the table is NULL
INSERT #PartialResult
(
[Target],
StartOrEnd,
PollTime,
GroupID
)
SELECT
FinalRow.[Target],
StartOrEnd = CONVERT(char(1), 'E'),
FinalRow.PollTime,
GroupID = LastGroup.GroupID
FROM
(
SELECT TOP (1)
T1.[Target],
T1.PollTime,
T1.Value
FROM dbo.Table1 AS T1
ORDER BY
T1.[Target] DESC,
T1.PollTime DESC
) AS FinalRow
CROSS APPLY
(
SELECT TOP (1) GroupID
FROM #PartialResult
ORDER BY GroupID DESC
) AS LastGroup
WHERE
FinalRow.Value IS NULL;

Solution step 3:
-- Final result
SELECT
Pivoted.[Target],
StartDate = Pivoted.S,
EndDate = Pivoted.E,
Duration = DATEDIFF(MINUTE, Pivoted.S, Pivoted.E)
FROM #PartialResult
PIVOT
(
MAX(PollTime)
FOR StartOrEnd IN (S, E)
) AS Pivoted
ORDER BY
Pivoted.GroupID;

-- Tidy up
DROP TABLE
#PartialResult,
dbo.Table1;
Results:
╔════════╦═════════════════════════╦═════════════════════════╦══════════╗
║ Target ║ StartDate ║ EndDate ║ Duration ║
╠════════╬═════════════════════════╬═════════════════════════╬══════════╣
║ A ║ 2013-12-13 13:34:44.000 ║ 2013-12-13 13:36:44.000 ║ 2 ║
║ B ║ 2013-12-21 05:30:34.000 ║ 2013-12-21 05:33:34.000 ║ 3 ║
║ B ║ 2013-12-21 05:34:34.000 ║ 2013-12-21 05:36:34.000 ║ 2 ║
╚════════╩═════════════════════════╩═════════════════════════╩══════════╝