Apologies for the potentially confusing question title. I struggled to make it generic!
I am designing a wildlife recording database. An observer goes to a site and records the occurences of species on a date as part of a sample. You can have lots of samples over time at the same site. So a sample has an id, a siteid and a date etc. Each sample has a number of occurrences, which are the individual wildlife records - the species and (say) the number counted. A site is divided up in to several locations within the site (locations have a siteid) and the occurrences reference these locations - not the site directly. So occurrences have a sampleid, speciesid and locationid.
So occurrences reference both a sample and a location that need to belong to the same site for the data to be consistent. The only way I could ensure that all occurrences reference locations from the same site as the sample was to have both sample and location primary keys include the siteid and then occurrences to include siteid in its foreign key to them. Here's a screenshot below.
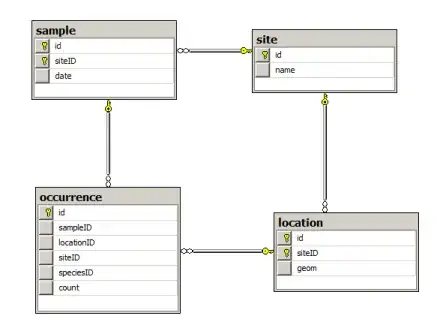
I have never needed to use compound primary keys in tables before and it jars a bit that occurrence has a siteID in it as part of the foreign key to both location and sample. Is this the correct way to constrain the locations and samples that occurrence can reference? Or is there an alternative table design that doesn't need compound keys? I don't have anything against compound keys if they're necessary. Are these ones necessary?