What is the MMM
First I want to explain the context for Brook's Law. What was the assumption that made him create it back in 1975?
A Man-month is a hypothetical unit of work representing the work done by one person in one month; Brooks' law says that it is impossible to measure useful work in man-months.
source: https://en.wikipedia.org/wiki/The_Mythical_Man-Month
Back in the day, complex programming projects would mean big monolith systems. And Brooks claims that these cannot be perfectly partitioned into discrete tasks that can be worked on without communication between developers and without establishing a set of complex interrelationships between tasks and the people performing them.
This is very much true in highly cohesive software monoliths. No matter how much decoupling is done, still the big monolith mandates time required for the new programmers to learn about the monolith. And increased communication overhead which will consume an ever increasing quantity of the time available.
But does it really have to be this way? Do we have to write monoliths and keep communication channels to n(n − 1) / 2 where n is the number of developers?
We know there are companies where thousands of developers are working on big projects ... and it does work. So there must be something that changed since 1975.
Possibility to mitigate the MMM
In 2015, PuppetLabs and IT Revolution published the results of the 2015 State of DevOps Report. In that report, they focussed on the distinction between high performing organizations vs. non-high performing.
The high-performing organizations show some unexpected properties. For example, they have the best project due-date performance in development. Best operational stability and reliability in operations. As well as the best security and compliance track record.
One of the surprising things highlighted in the report is the deployments per day metric. But not just deployments per day, they also measured deploy/day/developer and what is the effect of adding more developers in high-performing organizations vs. non-high performing.
This is the graph from that report -
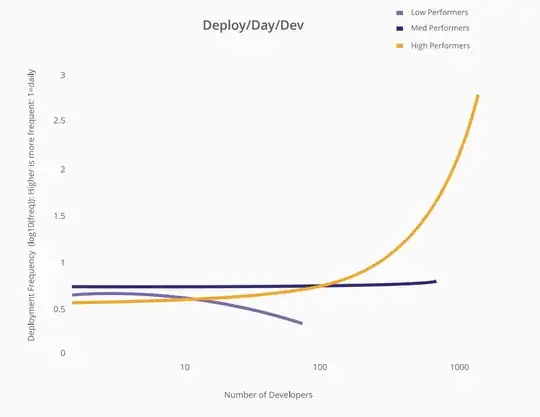
While low-performing organizations align with Mythical Man Month assumptions. The high-performing organizations can scale the number of deploy/day/dev linearly with the number of developers.
An excellent presentation at DevOpsDays London 2016 by Gene Kim talks about these findings.
How to do it
First, how to become a high-performing organization? There are a couple of books that talk about this, not enough space in this answer so I'll just link to them.
For software and IT organizations, one of the critical factors for becoming a high-performing organization is: focus on quality and speed.
For example Ward Cunningham explains Technical Debt as all the things we allowed to be left unfixed. This is accepted by management because it always comes with a promise that it is going to be fixed when there is time.
There is never enough time, and technical debt just becomes worse and worse.
What are these things that cause technical debt to grow?
- legacy code
- manual configuration of environments
- manual testing
- manual deployments
Legacy code As defined in Working Effectively with Legacy Code by Michael Feathers is any code that doesn't have automated testing.
Any time shortcuts are used to get the code to production; the operations is burdened with the maintenance of this debt forever. Then the process of deployment becomes longer and longer.
Gene tells a story in his presentation about a company who has six-week long deployments. Involving tens of thousands of extremely error prone tedious steps, tying up 400 people, and they would do this four times every year.
One of the tenets of DevOps is that reliability comes from doing smaller deployments more frequently.
Example
These two presentations show all the things that Amazon did to decrease the time it takes them to deploy code to production.
According to Gene, the only thing that is changed across time in these high-performing organizations is the number of developers. So from the Amazon example, you could say that in four years they increased their deployments ten times just by adding more people.
This means that under certain conditions, with the right architecture, the right technical practices, the right cultural norms, developer productivity can scale as the number of developers is increased. And DevOps is definitely in the middle of all this.
