We received an interesting "requirement" from a client today.
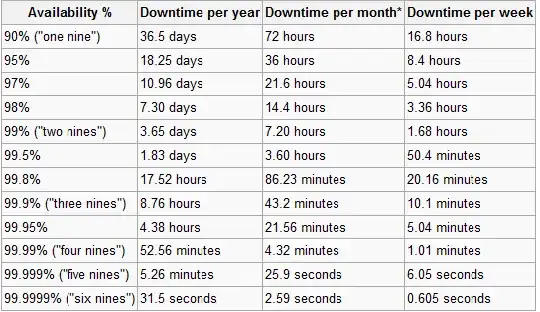
They want 100% uptime with off-site failover on a web application. From our web application's viewpoint, this isn't an issue. It was designed to be able to scale out across multiple database servers, etc.
However, from a networking issue I just can't seem to figure out how to make it work.
In a nutshell, the application will live on servers within the client's network. It is accessed by both internal and external people. They want us to maintain an off-site copy of the system that in the event of a serious failure at their premises would immediately pick up and take over.
Now we know there is absolutely no way to resolve it for internal people (carrier pigeon?), but they want the external users to not even notice.
Quite frankly, I haven't the foggiest idea of how this might be possible. It seems that if they lose Internet connectivity then we would have to do a DNS change to forward traffic to the external machines... Which, of course, takes time.
Ideas?
UPDATE
I had a discussion with the client today and they clarified on the issue.
They stuck by the 100% number, saying the application should stay active even in the event of a flood. However, that requirement only kicks in if we host it for them. They said they would handle the uptime requirement if the application lives entirely on their servers. You can guess my response.