I am currently checking through the syllabus for the ISTQB "Technical Test Analyst" certification. This syllabus (henceforth called "TTA syllabus") contains a chapter dedicated to "condition testing" (apparently this is also called "condition coverage" or "condition coverage testing".)
Condition testing as defined in the TTA syllabus strikes me as an exceedingly strange and possibly anachronistic thing that has more to do with Grandma's Ham Story than with software testing. Let me explain...
What is "condition testing" according to the TTA syllabus?
Referring to the "Advanced Level Syllabus - Technical Test Analyst, Version 2012" of the ISTQB, available here, "condition testing" is defined as follows on page 12:
Compared to decision (branch) testing, which considers the entire decision as a whole and evaluates the TRUE and FALSE outcomes in separate test cases, condition testing considers how a decision is made. Each decision predicate is made up of one or more simple “atomic” conditions, each of which evaluates to a discrete Boolean value. These are logically combined to determine the final outcome of the decision. Each atomic condition must be evaluated both ways by the test cases to achieve this level of coverage.
Applicability
Condition testing is probably interesting only in the abstract because of the difficulties noted below. Understanding it, however, is necessary to achieving greater levels of coverage that build upon it.
So let's clarify the words
Suppose we have some software-under-test on which we want to do whitebox testing (i.e. we have the source code). The code naturally contains many of those decision predicates that we all know and love and that show up after strings like if, while, until etc.
An example of the decision predicate might be:
((x>y+z) AND (y<-3)) OR ((z²+x²<4) AND (z≤y))
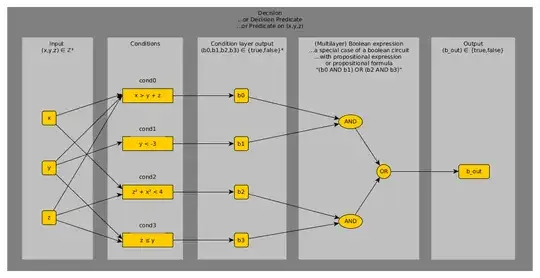
This decision predicate accepts a triple (x,y,z) of integer values (say) and outputs a boolean, b_out.
The first-level functions which map (x,y,z) to {TRUE,FALSE} are called conditions (also atomic conditions) in the TTA syllabus.
Condition testing coverage
One attains "condition testing coverage" by running test cases until all the conditions found in the decision yielded at least once true and at least once false.
One can thus achieve condition testing coverage by running the following five test cases (for example):

Each of the the b0, b1, b2, b3 shows up at least once with true and at least once with false. In some test cases, we do not care about a given value as it has no influence on the condition whose output we want to get right.
Addendum: Decision coverage
Incidentally, the truth table shows also that "decision coverage" has been attained for this decision, as b_out shows up at least once with true and at least once with false, so both branches of any code would be covered.
And now the question
What is "condition testing" as defined above actually good for?
It won't help you ascertain the correctness of the decision predicate at all.
That is best done by a code inspection, letting a second team write the same expression and comparing outputs or running test cases at "boundary values" (e.g. here, for y = -4, -3, -2).
Checking the individual conditions strikes me to be more about testing the CPU's ALU or maybe testing the compiler output. It is certainly suitable for checking manually written assembler code or verifying manually assembled logic.
And this makes me think that "condition testing" could well be a leftover from the days where conditions were actually wired up on panels (for example in the ENIAC) and might thus be subject to wiring bugs. These days, the condition is written in high-level code and is exactly the one you conceptually want. While review might be useful, a testing of the condition is just a waste of time.
Or am I missing something?
Addendum: Literature Search
A search of the IEEE Xplore library for "condition testing" yields only two papers relevant to software (all the others seem relevant to hardware only), both by K.C. Tai of the Department of Computer Science of North Carolina State University.
Checking one of those, Condition-based software testing strategies reveals that the author uses the term condition in the sense of decision above, i.e. in this paper "condition testing" is actually "decision testing". The condition as used in the TTA syllabus is called simple condition. It seems the TTA syllabus definitions are not widely used.
From the abstract:
A computer program consist of statements, such as IF and WHILE statements, that contain conditions, which are combinations of Boolean and relational expressions. A testing approach, referred to as condition testing, is to test a program by focusing on testing the conditions in this program. A number of condition testing strategies have been developed, but they are not effective for detecting errors in complicated conditions. In this paper, we define two condition testing strategies, based on the detection of Boolean and relational expression [i.e. expression of the form E1 op E2, where E1 and E2 are arithmetic expressions and op is one of six possible relational operators: < <=, =, !=, >, >=] errors in a condition. For these two condition testing strategies, we show some theoretical properties and explain why they are practical and effective for testing programs containing complicated conditions.