Note: See "EDIT" for the answer to the current question
First of all, read Subversion Re-education by Joel Spolsky. I think most of your questions will be answered there.
Another recommendation, Linus Torvalds' talk on Git: http://www.youtube.com/watch?v=4XpnKHJAok8. This other one might also answer most of your questions, and it is quite an entertaining one.
BTW, something I find quite funny: even Brian Fitzpatrick & Ben Collins-Sussman, two of the original creators of subversion said in one google talk "sorry about that" referring to subversion being inferior to mercurial (and DVCSs in general).
Now, IMO and in general, team dynamics develop more naturally with any DVCS, and an outstanding benefit is that you can commit offline because it implies the following things:
- You don't depend on a server and a connection, meaning faster times.
- Not being slave to places where you can get internet access (or a VPN) just to be able to commit.
- Everyone has a backup of everything (files, history), not just the server. Meaning anyone can become the server.
- You can commit compulsively if you need to without messing others' code. Commits are local. You don't step on each other's toes while committing. You don't break other's builds or environments just by committing.
- People without "commit access" can commit (because commiting in a DVCS does not imply uploading code), lowering barrier for contributions, you can decide to pull their changes or not as an integrator.
- It can reinforce natural communication since a DVCS makes this essential... in subversion what you have instead are commit races, which force communication, but by obstructing your work.
- Contributors can team up and handle their own merging, meaning less work for integrators in the end.
- Contributors can have their own branches without affecting others' (but being able to share them if necessary).
About your points:
- Merging hell doesn't exist in DVCSland; doesn't need to be handled. See next point.
- In DVCSs, everyone represents a "branch", meaning there are merges everytime changes are pulled. Named branches are another thing.
- You can keep using continuous integration if you want. Not necessary IMHO though, why add complexity?, just keep your testing as part of your culture/policy.
- Mercurial is faster in some things, git is faster in other things. Not really up to DVCSs in general, but to their particular implementations AFAIK.
- Everyone will always have the full project, not only you. The distributed thing has to do with that you can commit/update locally, sharing/taking-from outside your computer is called pushing/pulling.
- Again, read Subversion Re-education. DVCSs are easier and more natural, but they are different, don't try to think that cvs/svn === base of all versioning.
I was contributing some documentation to the Joomla project to help preaching a migration to DVCSs, and here I made some diagrams to illustrate centralized vs distributed.
Centralized

Distributed in general practice

Distributed to the fullest
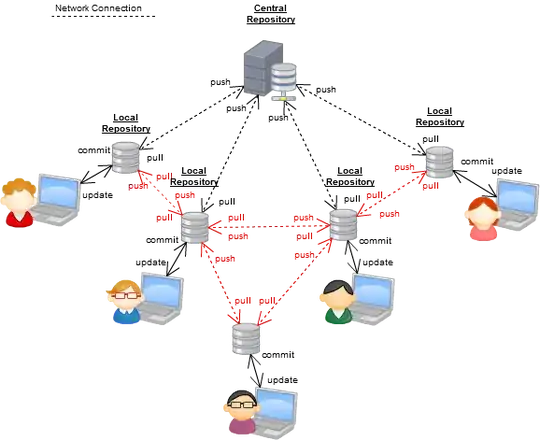
You see in the diagram there is still a "centralized repository", and this is one of centralized versioning fans favourite arguments: "you are still being centralized", and nope, you are not, since the "centralized" repository is just repository you all agree on (e.g. an official github repo), but this can change at any time you need.
Now, this is the typical workflow for open-source projects (e.g. a project with massive collaboration) using DVCSs:
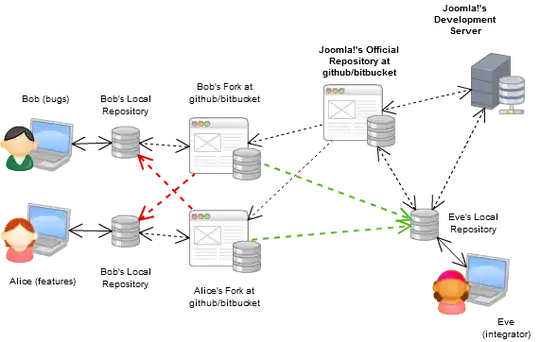
Bitbucket.org is somewhat of a github equivalent for mercurial, know that they have unlimited private repositories with unlimited space, if your team is smaller than five you can use it for free.
The best way you can convince yourself of using a DVCS is trying out a DVCS, every experienced DVCS developer that has used svn/cvs will tell you that is worth it and that they don't know how they survived all their time without it.
EDIT: To answer your second edit I can just reiterate that with a DVCS you have a different workflow, I'd advise you not to look for reasons not to try it because of best practices, it feels like when people argue that OOP is not necessary because they can get around complex design patterns with what they always do with paradigm XYZ; you can benefit anyways.
Try it, you'll see how working in "a private branch" is actually a better option. One reason I can tell about why the last is true is because you lose the fear to commit, allowing you to commit at any time you see fit and work a more natural way.
Regarding "merging hell", you say "unless we are experimenting", I say "even if you are experimenting + maintaing + working in revamped v2.0 at the same time". As I was saying earlier, merging hell doesn't exist, because:
- Everytime you commit you generate an unnamed branch, and everytime your changes meet other persons' changes, a natural merge occurs.
- Because DVCSs gather more metadata for each commit, less conflicts occur during merging... so you could even call it an "intelligent merge".
- When you do bump into merge conflicts, this is what you can use:

Also, project size doesn't matter, when I switched from subversion I actually was already seeing the benefits while working alone, everything just felt right. The changesets (not exactly a revision, but a specific set of changes for specific files you include a commit, isolated from the state of the codebase) let you visualize exactly what you meant by doing what you were doing to a specific group of files, not the whole codebase.
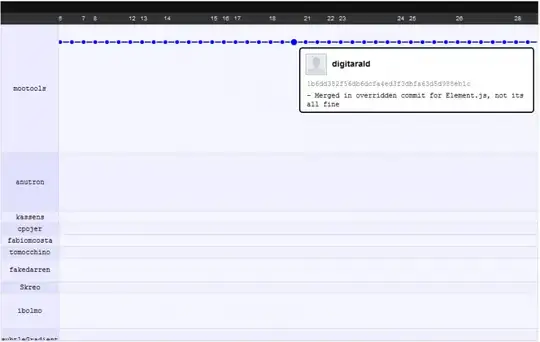
Regarding how changesets work and the performance boost. I'll try to illustrate it with an example I like to give: the mootools project switch from svn illustrated in their github network graph.
Before
After
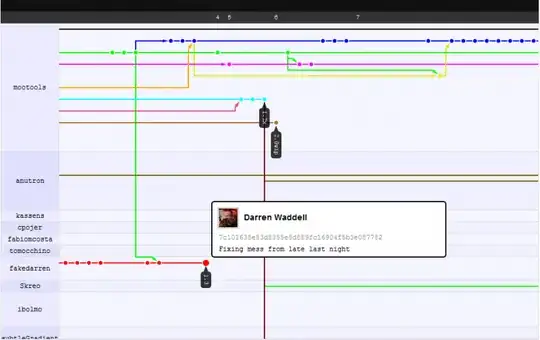
What you are seeing is developers being able to focus on their own work while commiting, without the fear of breaking others' code, they worry about breaking others' code after pushing/pulling (DVCSs: first commit, then push/pull, then update) but since merging is smarter here, they often never do... even when there is a merge conflict (which is rare), you only spend 5 minutes or less fixing it.
My recommendation to you is to look for someone that knows how to use mercurial/git and to tell him/her to explain it to you hands-on. By spending about half an hour with some friends in the command line while using mercurial with our desktops and bitbucket accounts showing them how to merge, even fabricating conflicts for them to see how to fix in a ridiculous ammount of time, I was able to show them the true power of a DVCS.
Finally, I'd recommend you to use mercurial+bitbucket instead of git+github if you work with windows folks. Mercurial is also a tad more simple, but git is more powerfull for more complex repository management (e.g. git rebase).
Some additional recommended readings: